ML Experiment Log: Squaring as activation layer
I'm a freelance full stack developer with 10 years experience.
Generative design with machine learning is something I'm interested in and researching in my free time.
The purpose of an activation layer is to add some non-linearity to the network. This allows expressing much more complex tasks with our networks.
But why do we generally use functions that have a low/zero less than zero component and a nearly 1 component for positive inputs?
I think on the surface it makes some sense, but I question whether we really want those characteristics in our activation functions.
In this experiment I'm checking out squaring as an activation function on MNIST. I think squaring as an activation function would allow a kind of symbolic compression of the network after training that relu does not. On top of that, squaring is simpler than many activation functions to compute.
Experiment
As a starting point, I'm using this code. It's a simple non-conv neural network with a single hidden layer and relu activation.
For this experiment, I'll compare loss with relu, squaring and no activation. I'm expecting relu to perform the best, with squaring nearly as good, and no-activation performing much more poorly.
When training (once) with relu, we get the following output.
Results
ReLU and Squaring perform very similarly, with no-activation performing worst. I think it's good to keep in mind how simple this problem really is, and as such more experiments in this direction would be warrented before really drawing a conclusion. However as a sanity check, to me this shows a squaring based activation function may be worth checking out. In the next section I'll explain why I think despite similar performance squaring would be a big advantage over relu.
Relu
Epoch 1/6
469/469 [==============================] - 2s 4ms/step - loss: 0.3597 - sparse_categorical_accuracy: 0.9017 - val_loss: 0.1950 - val_sparse_categorical_accuracy: 0.9446
Epoch 2/6
469/469 [==============================] - 2s 4ms/step - loss: 0.1661 - sparse_categorical_accuracy: 0.9523 - val_loss: 0.1324 - val_sparse_categorical_accuracy: 0.9630
Epoch 3/6
469/469 [==============================] - 2s 4ms/step - loss: 0.1192 - sparse_categorical_accuracy: 0.9659 - val_loss: 0.1095 - val_sparse_categorical_accuracy: 0.9678
Epoch 4/6
469/469 [==============================] - 2s 4ms/step - loss: 0.0921 - sparse_categorical_accuracy: 0.9735 - val_loss: 0.0954 - val_sparse_categorical_accuracy: 0.9704
Epoch 5/6
469/469 [==============================] - 2s 4ms/step - loss: 0.0744 - sparse_categorical_accuracy: 0.9784 - val_loss: 0.0877 - val_sparse_categorical_accuracy: 0.9736
Epoch 6/6
469/469 [==============================] - 2s 4ms/step - loss: 0.0625 - sparse_categorical_accuracy: 0.9818 - val_loss: 0.0792 - val_sparse_categorical_accuracy: 0.9756
<keras.callbacks.History at 0x7fe184770690>
Square
Epoch 1/6
469/469 [==============================] - 12s 6ms/step - loss: 0.2814 - sparse_categorical_accuracy: 0.9233 - val_loss: 0.1297 - val_sparse_categorical_accuracy: 0.9640
Epoch 2/6
469/469 [==============================] - 2s 4ms/step - loss: 0.1132 - sparse_categorical_accuracy: 0.9690 - val_loss: 0.1238 - val_sparse_categorical_accuracy: 0.9658
Epoch 3/6
469/469 [==============================] - 2s 4ms/step - loss: 0.0796 - sparse_categorical_accuracy: 0.9770 - val_loss: 0.0991 - val_sparse_categorical_accuracy: 0.9706
Epoch 4/6
469/469 [==============================] - 2s 4ms/step - loss: 0.0589 - sparse_categorical_accuracy: 0.9829 - val_loss: 0.1038 - val_sparse_categorical_accuracy: 0.9726
Epoch 5/6
469/469 [==============================] - 2s 4ms/step - loss: 0.0468 - sparse_categorical_accuracy: 0.9861 - val_loss: 0.1102 - val_sparse_categorical_accuracy: 0.9726
Epoch 6/6
469/469 [==============================] - 2s 4ms/step - loss: 0.0405 - sparse_categorical_accuracy: 0.9877 - val_loss: 0.0947 - val_sparse_categorical_accuracy: 0.9754
<keras.callbacks.History at 0x7fe18505eb10>
No-Activation
Epoch 1/6
469/469 [==============================] - 4s 6ms/step - loss: 0.3875 - sparse_categorical_accuracy: 0.8903 - val_loss: 0.2986 - val_sparse_categorical_accuracy: 0.9156
Epoch 2/6
469/469 [==============================] - 3s 6ms/step - loss: 0.2902 - sparse_categorical_accuracy: 0.9186 - val_loss: 0.2908 - val_sparse_categorical_accuracy: 0.9173
Epoch 3/6
469/469 [==============================] - 2s 4ms/step - loss: 0.2777 - sparse_categorical_accuracy: 0.9226 - val_loss: 0.2901 - val_sparse_categorical_accuracy: 0.9211
Epoch 4/6
469/469 [==============================] - 2s 4ms/step - loss: 0.2709 - sparse_categorical_accuracy: 0.9250 - val_loss: 0.2833 - val_sparse_categorical_accuracy: 0.9215
Epoch 5/6
469/469 [==============================] - 2s 4ms/step - loss: 0.2672 - sparse_categorical_accuracy: 0.9249 - val_loss: 0.2794 - val_sparse_categorical_accuracy: 0.9228
Epoch 6/6
469/469 [==============================] - 2s 4ms/step - loss: 0.2626 - sparse_categorical_accuracy: 0.9271 - val_loss: 0.2744 - val_sparse_categorical_accuracy: 0.9260
The modified code for this can be found here.
Other Advantages to Squaring
Taking a simple network with a single hidden layer with activation, let's do a bit of symbolic math.
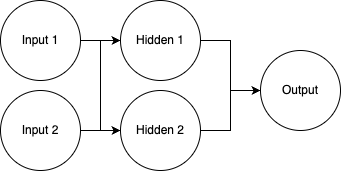
Given this network, if we have no activation layers, the output can be simplified as follows.
output = h1 * w211 + hidden 2 * w212 + b21
# Hidden node values
h1 = input1 * w111 + input2 * w112 + b11
h2 = input1 * w121 + input2 * w122 + b12
# Simplify
output = b21 +
input1 * w111 * w211 + input 2 * w112 * w211 + w211*b11 +
input1 * w121 * w212 + input2 * w122 * w212 + b12 * w212
output = (b21 + w211*b11 + w212*b12) + input1 * (w121*w212 + w111*w211) + input2 * (w122*w212 + w112*w211)
# Noting we can pre-calculate some of this for very simple runtime evaluation
output = c + input1 * c2 + input3 * c3
This type of simplification of the network doesn't work with relu, as we need to basically have some conditional logic in our output calculation.
Squaring however leads to a different outcome, less simple than the no-activation case, but still simple. This allows a much faster runtime evaluation.
