

ML Experiment Log - Deep Learning Alternative Approach
Evolving architecture as part of training


Before we get started, I don't have great test results to show here. I'm largely showing an idea I have, and the code I've created to experiment with it.
To start, let's talk about one of the largest downsides in the way deep learning often works at the moment.
- Define an architecture
- Train the architecture on the data
- If you want to use transfer learning, lop off the last few layers and retrain (more options here, but keeping it simple)
One of the biggest pieces missing here in my opinion is a search for architectures that have a good inductive bias.
The idea
Let's create an algorithm that changes topology as it trains, rather than starting fixed and staying fixed.
To accomplish this, we'll do something like the following.
loop
trainOneEpoch
pruneNetwork
evolveNetwork
Where prune network removes parts that don't seem to have a big impact on the outputs for the benchmark dataset, and evolveNetwork adds a random mutation to the network.
The code
Several key notes about implementation
- Prune based on stddev of a connections final layer output (ignoring ops that aren't leafs)
- Evolve by generating a random connection
- Op is sum or multiply, though can certainly choose other ops.
Op
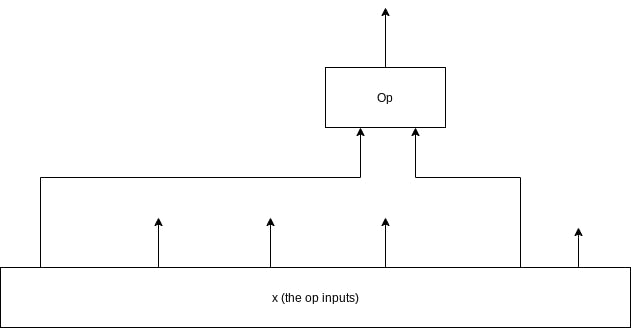
For our smallest unit, we have a specific op instance. This basically represents using an op like sum or multiply on 2 values. These 2 values may be a trainable parameter or an specific input column from the input matrix. It outputs a 1d array of size (batchSize) that's the output of the operation.
class EvOp(torch.nn.Module):
# op is a function taking 2 arguments
# p1,p2 are arguments describing position in the x input array that the value should come from
# or if not, initialize a trainable paramater as 0.
def __init__(self, op, p1, p2, attn=True, device="cpu"):
super(EvOp, self).__init__()
self.op = op
if p1:
self.p1 = p1
else:
self.p1 = torch.nn.Parameter(0.)
self.p1.requires_grad = True
if p2:
self.p2 = p2
else:
self.p2 = torch.nn.Parameter(0.)
self.p2.requires_grad = True
# decrement indexes above reduces the index of any
# parameters above the ind value.
# This is primarily for when we're pruning the network, and we remove
# a value in the middle of our outputs
def decrement_indexes_above(self, ind):
if isinstance(self.p1, int):
if self.p1 > ind:
self.p1 = self.p1-1
if isinstance(self.p2, int):
if self.p2 > ind:
self.p2 = self.p2-1
# forward takes an input x of shape (batchSize, inputSize) and outputs
# a value of shape ()
def forward(self, x):
p1 = self.p1 * torch.ones_like(x[..., 0])
if isinstance(self.p1, int):
p1 = x[..., self.p1]
p2 = self.p2 * torch.ones_like(x[..., 0])
if isinstance(self.p2, int):
p2 = x[..., self.p2]
res = self.op(p1, p2)
# This isn't good for small batch sizes. Batch norm would likely be a better
# option
return torch.nn.functional.normalize(res, dim=0)
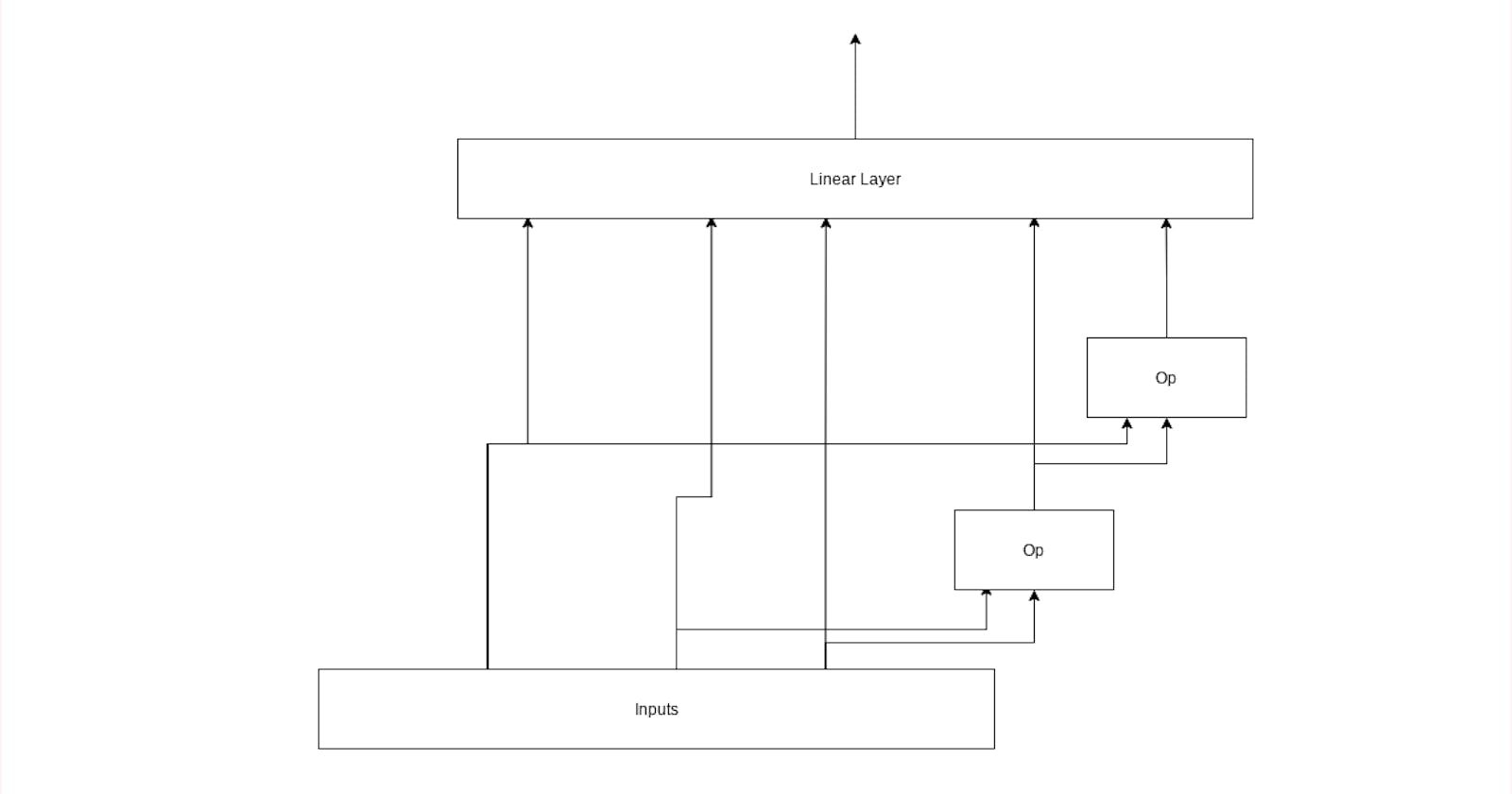
Layer
For our base layer, this will handle a few things.
- Evolving, create a new operation to perform and setting it up.
- Pruning, remove an op that looks like it's having the smallest impact on output of layer.
- Wire the ops together, pass output of previous ops to later ops.
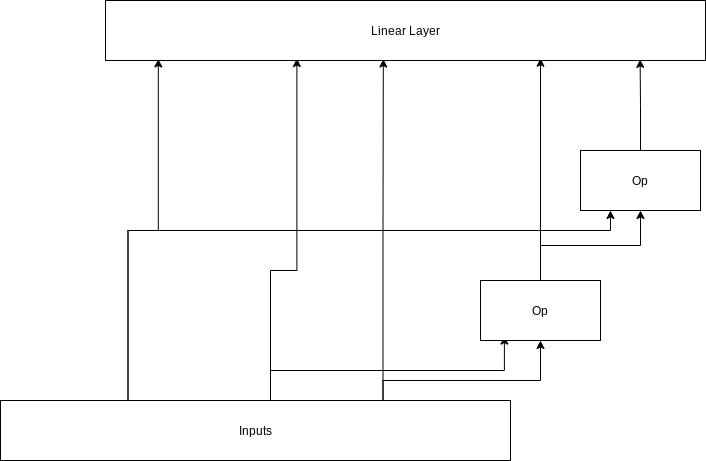
Gathering inputs for an operation
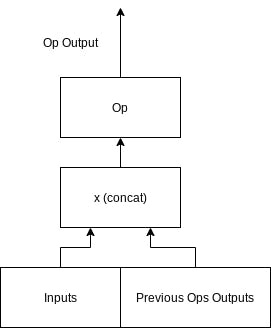
Putting the pieces together for layer output
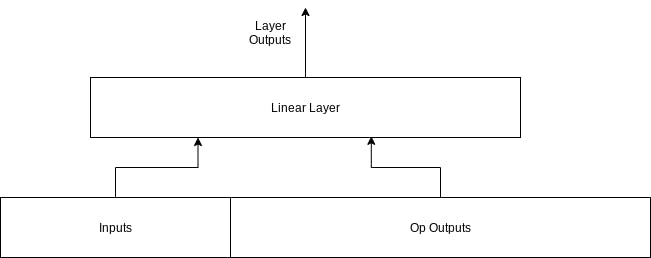
With the overall inputs/ops/outputs looking something like this.
import random
import copy
possible_ops = [torch.add, torch.mul]
# EvLayer uses a linear layer to get the correct input/output dimensions
# Input to the linear layer is the inputs + op outputs.
class EvLayer(torch.nn.Module):
def __init__(self, input_dims=2, output_dims=3, ops=torch.nn.ModuleList([])):
super(EvLayer, self).__init__()
self.ops = ops
self.input_dims = input_dims
self.output_dims = output_dims
self.out = torch.nn.Linear(input_dims + len(ops), output_dims)
# Find the list of operations that don't have another op depending on them.
def leaf_ops(self):
not_leaf_ops = []
for _,op in enumerate(self.ops):
if isinstance(op.p1, int) and op.p1 > self.input_dims:
not_leaf_ops.append(self.input_dims - op.p1)
if isinstance(op.p2, int) and op.p2 > self.input_dims:
not_leaf_ops.append(self.input_dims - op.p2)
mask = torch.zeros((len(self.ops)), device=self.out.weight.device)
for k in not_leaf_ops:
mask[k] = 1.
return mask
# evolve makes a copy of the layer, prunes and evolves the network. It only prunes if an input x was provided.
def evolve(self, x):
rm_op = None
# Run the layer on the input x if present.
# Calculate stddev, and find the leaf op that has the lowest stddev.
if x is not None and x[:, self.input_dims:].size(1) > 1:
per_op_weight = torch.sum(self.out.weight[:, self.input_dims:], dim=0)
diff_amounts = per_op_weight * x[:, self.input_dims:]
stddev = torch.std(diff_amounts, dim=0)
mask = self.leaf_ops()
stddev2 = stddev + mask * 1000 # basically just trying to mask, I'm too lazy to work with max int32 atm
rm_op = torch.argmin(stddev2)
print("Avg Stddev: ", torch.mean(stddev), " RmOp: ", rm_op, " Type: ", self.ops[rm_op].op.__name__, " MaskAvg: ", torch.mean(mask))
# Deep copy ops
ops = copy.deepcopy(self.ops)
out = copy.deepcopy(self.out)
# Pull out loser in stddev
if rm_op is not None:
for op in ops[rm_op:]:
op.decrement_indexes_above(rm_op)
# Remove the corresponding weights of the op from the linear layer.
if rm_op == len(ops):
out.weight = torch.nn.Parameter(out.weight[:, :rm_op])
else:
out.weight = torch.nn.Parameter(torch.cat([out.weight[:, :rm_op], out.weight[:, rm_op+1:]], dim=1))
del ops[rm_op]
# Choose a random operation type from possible operations
new_op = random.choice(possible_ops)
p1, p2 = None, None
param_count = len(ops) + self.input_dims
if random.randrange(3):
p1 = random.randrange(param_count)
# set p2 if p1 is going to be a variable not an index so we don't end up with variable/variable and basically have an extra constant in our variable list
if (not p1) or random.randrange(3):
p2 = random.randrange(param_count)
new_op = EvOp(new_op, p1, p2, device=out.weight.device)
ops.append(new_op)
print("Adding new op: ", new_op)
ev = EvLayer(self.input_dims, self.output_dims, ops)
ev.out = out
# Add 1 to our linear layer inputs to account for the new op
ev.out.weight = torch.nn.Parameter(torch.cat((out.weight, torch.zeros(self.output_dims, 1, device=out.weight.device)), 1))
return ev
# For each op, take the inputs + previous_ops and pass it into the op.
# Take the output and save it for input into the next ops.
# Return the combined outputs at the end.
def forward(self, x):
for _, op in enumerate(self.ops):
opres = op(x)
x = torch.cat([x, torch.unsqueeze(opres, dim=-1)], dim=len(x.size())-1)
return self.out(x), x
Pros
- Search's for architecture with inductive bias.
- Likely easy to ensemble with other runs of the same algorithm for better results.
- Potentially more memory efficient for equal accuracy.
- Potentially a good candidate for distributed CPU based training.
Cons
- Likely difficult/impossible to make quite as efficient than current architectures, both in runtime and in train time. Huge negative, though I think there's a lot of optimization that can get us close.
- Likely susceptible to over fitting. Another huge negative, but also one we can combat in various ways.
Conclusion
This could be an approach with similar results, and very different train/runtime characteristics from more standard ml.
The project I'm using to test this isn't ready for release (and has mixed results), I may do a follow up post with more testing.
If you found it interesting or have any thoughts I'd love to hear from you in the comments or via the contact form.
PS: I'd love to work with a company doing research as an ML engineer/researcher, let's get in contact if you're interested.